



If you came to this post from my Facebook you’ve been participating in a little not-so-scientific experiment on my behalf.
For most of the month of January almost all of my Facebook shares have passed through a new site I set up with WordPress and PressForward. On Chronoto.pe I archive a copy of everything I’ve read and those archives are what I’ve been sharing to my Facebook page.
Why?
Because how Facebook decides what gets presented to you on a daily basis is sort of a mystery. Some posts are more likely to show up than others, some posts will come back to the top of your stream hours, days or even weeks after they were originally shared. Like almost everything that decides what’s important to you on the internet (Google, the most notable of the group) Facebook considers the algorithm it uses to present content a competitive advantage and keeps the specifics of it a secret. We know something about it because of what we see, others have found and Facebook itself provides.
Some Facebook stats are available, but almost entirely they are focused on pages. What about humans? What decisions does Facebook make about what we share?
What did I find?
Today I’m sharing the some of the data I found from my first two weeks of the experiment. This is a pretty short time, so I’m take my conclusions and hypotheses for follow-up with a grain of salt. I don’t have a huge Facebook following, but I think mine is larger than normal, so that might change things to when it comes to how Facebook treats me as an individual.
Over the first two weeks of my experiment, I saw 1,758 clicks on the links I shared, with Google Analytics marking 1,304 Users across that time.
Looking at that data, I got some ideas.
Facebook’s most important measure is probably click-throughs. Achieve more than 25% of the previous day, and people will see your post tomorrow.
With a significant amount of consistency, the count of people who clicked on articles was the most important measure for determining the continuing popularity of a post. Almost every post was clicked the day it was posted and the day after. If the number of clicks exceeded 25% of the previous day, it usually got clicks the day after. If they didn’t, it didn’t get any clicks the following day. I’m assuming Facebook is pretty good at getting people to click on things, so I’m betting Facebook doesn’t present, or rarely presents, content falling below that threshold.
Hypothesis: Likes matter more with very short or very long posts.
In the set of links I looked at, click-through rates seemed to be more closely connected to the Like count when the post was very long (4 or more lines) or very short (1 line). A lot more experimentation is required to confirm this.
Hypothesis: Comments don’t matter.
I had some pretty active comment threads over this period, with variety when it came to the number of different participants. As far as I can tell, the number of comments or commenters didn’t significantly matter when it came to a post’s popularity. Probably a bad sign if you set up a site with Facebook comments in the hope it would increase the site’s popularity.
Hypothesis: Reshares don’t matter (for your thread).
A few of the articles I shared were re-shared by others. The activity on those new posts were still traceable, but the resulting activity didn’t seem like it added to my own post, instead it acted like a new post. Facebook will occasionally aggregate multiple posts around one link into a single thread, it did so with my links at least one time I saw, but the top post seems to always be the most recently posted, which makes it unlikely that anyone will engage with your original post.
Hypothesis: Peak consumption is between 1 and 3pm, but when you share doesn’t matter.
I saw absolutely no correlation between the popularity of an article and when I shared it. Further sharing past the first two weeks towards the present has been about testing this hypothesis by targeting this optimal window, I’ll share those results at a later point but it seems consistent with this idea, that a particular sharing time doesn’t mean much.
Hypothesis: Facebook use is heavily mobile.
This one is pretty much heavily proved out by every media company that reports stats, but it was consistent with what I saw on my page as well. During these two weeks, 60% of clicks were from mobile users. 87% of those users were on Apple or Samsung devices.
Some additional thoughts on the results:
Google Analytics seems tremendously inaccurate. I know this sort of makes a mess out of trying to figure out stats using it, but I have to say it here. GA recorded an average read time on my site of multiple minutes, but every page other than the very rarely visited archive pages forwards users within 1 second. Some of these individual article pages recorded an incredibly high average read time, at least one exceeded 15 minutes. This is impossible.
I have always suspected that the never-ending trumpeting of things like engagement seconds seemed incredibly suspect, and while I don’t have enough data here to stomp around calling bullshit, I’m going to say that those stats are not as accurate as you might think. On larger sites I’ve seen huge differences around time-on-page statistics between different analytics packages, and no explanation why. Whatever differing methodologies these other analytics tools use, I wouldn’t bet my life on the accuracy of any of them.
Analytic reports around new users seemed suspect too. I understand that different devices get counted as different users, but though my friends count of 934 is ego-boosting, the new user count provided by Google Analytics seems too high. By the same measure, the difference between Pageviews and Unique Pageviews seems optimistic considering that every Facebook-based pageview that came to the site would be a self-terminating session.
How?
There are limits to what I can determine on Facebook, but I’ve focused on that most important currency of the modern media world, the Facebook link share. To those not overly obsessed with media or technology this may sound like a boring focus, but Facebook shares and links drive the internet. Facebook posts and chat comprise the majority of social traffic to most major media sites and it seems like they lead overall traffic sources for some.
The first thing I discovered when I started this experiment is that Facebook decides what a link is in a way differently then you might imagine. Once you’ve posted a URL inside that post box, Facebook sends a crawler to that web page and looks first for two properties in the HEAD section of the page.
-
canonical
-
og:url
It also checks to see if the page is, in some way, forwarded elsewhere though redirect headers.
If any of these three elements are present, Facebook isn’t going to be sharing the URL you put in to the page, it’s going to share a different one instead. The one listed in one of those HEAD meta-properties or the page redirected to. Not only that, it is going to treat it as a different URL, and even that treatment may be different depending on the redirect method.
The first two methods may have code that looks like this:
<link rel="canonical" href="http://jezebel.com/be-suspicious-of-the-new-harper-lee-novel-1683488258" />
<meta property="og:url" content="http://jezebel.com/be-suspicious-of-the-new-harper-lee-novel-1683488258" />Now you may not realize it, but you see a ton of 301 redirects on Facebook, they’re created with any shortened link, like the ones provided by bit.ly. They wouldn’t really look like anything if you were able to see them in your browser, but when computers hit those pages, they see a header that redirect them. Those headers look like:
<?php
# via var_dump(wp_remote_get('http://nzzl.me/1xqgPpn',array('redirection' => 0)));
array(5) {
["headers"]=>
array(9) {
["server"]=>
string(5) "nginx"
["date"]=>
string(29) "Tue, 03 Feb 2015 22:34:52 GMT"
["content-type"]=>
string(24) "text/html; charset=utf-8"
["content-length"]=>
string(3) "147"
["connection"]=>
string(5) "close"
["cache-control"]=>
string(19) "private, max-age=90"
["location"]=>
string(55) "http://www.vox.com/2015/1/3/7482623/emerson-spartz-dose"
["mime-version"]=>
string(3) "1.0"
["set-cookie"]=>
string(100) "_bit=54d14d0c-0018d-06e9b-301cf10a;domain=.nzzl.me;expires=Sun Aug 2 22:34:52 2015;path=/; HttpOnly"
}
["body"]=>
string(147) "
moved here
"
["response"]=>
array(2) {
["code"]=>
int(301)
["message"]=>
string(17) "Moved Permanently"
}
["cookies"]=>
array(1) {
[0]=>
object(WP_Http_Cookie)#344 (6) {
["name"]=>
string(4) "_bit"
["value"]=>
string(29) "54d14d0c-0018d-06e9b-301cf10a"
["expires"]=>
int(1438554892)
["path"]=>
string(1) "/"
["domain"]=>
string(8) ".nzzl.me"
["httponly"]=>
string(0) ""
}
}
["filename"]=>
NULL
}In either case, Facebook will treat this link like whatever URL it is forwarding or pointing to. So though all the links I shared were to my own site, anyone who looked at my wall would see a link, complete with all OpenGraph data, displaying the original article. Once they clicked through, Facebook would send users to my site, where another piece of code would redirect them after waiting 1 second so Google Analytics would record their info. I store all the remote article’s OG data on my own site, but I wouldn’t need to. After FB sees one of these three properties it stops and goes to the page those properties are pointing at, retrieving all the OG information from there.
Things start getting a little weird after that.
People who share your link share the URL you added, not the ‘terminal’ (I’m using this term to mean the page the user ends up on) URL. I examined the people who re-shared my content and I found that their shares led through my site as well. Additionally, when Facebook pulls together a whole bunch of posts into one of those “X and Y others shared a link” aggregation posts, the person whose comment is on top is the one who determines the link. When I was on top, the link went through my system. When others were, it worked differently.
No matter what, Facebook considers your shares as from the terminal site. So my shares are considered by Facebook’s system, whenever I could see, from the terminal site; for example they would show up with the source of nytimes.com instead of chronoto.pe.
Theoretically, this is pretty awesome, it allows link shorteners to do their thing and aggregation sites to properly pass credit on to the origin when they care to do so.
It’s also important to note that this behavior is consistent with how it works on Google+ and LinkedIn.
In reality, there are two big problems here.
The first — and I hesitate to say this because I like the idea of a nice, open and trusting web — what if I was a malicious website builder? I can’t figure out why it isn’t possible set the canonical or og:url properties without the redirect and rake up a bunch of pageviews to a site that shares as one thing on Facebook and is another thing when you click through. I assume it would get reported and found out that way, but there would be a period where it wouldn’t be, right? When I tested this with the Facebook’s Open Graph Object debugger, this potentially malicious behavior seemed possible.
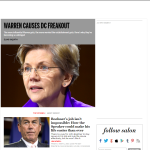
The second is that Facebook treats my meta-data redirect exactly as expected, but it treats the more precise 301 redirect differently (in some cases). Specifically it seems to mark the source as the redirecting page, not the terminal page. Resulting in something like what we see in the below image, where Facebook sources a New York Times article to a bit.ly-based link shortener. This doesn’t happen every time, and I have no idea why it does in some cases or does not in others. It may have to do with when something is shared (Facebook’s caching problems) or something having to do with sharing from Facebook applications. This is worth looking into more and I’ll be playing with it.
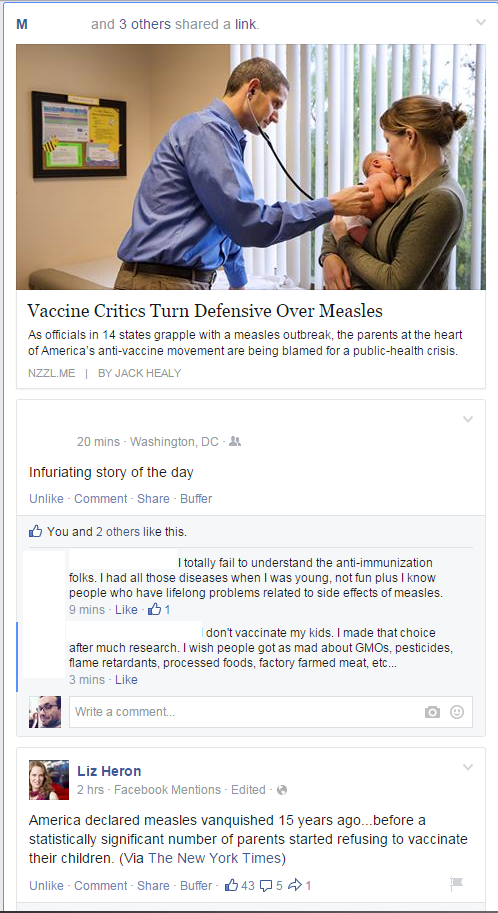
The aggregation of posts based on URL displays the top sharer’s version of that URL.
Another thing I noticed while I was playing around with the display of this information? The author value after “By” is only set using a non-Open Graph meta tag.
Specifically:
<meta name="author" content="Jack Healy">
This is really weird. This isn’t an OpenGraph tag. This tag is, according to most reports, ignored by Google. It’s absolutely ignored by search engine optimizers, as it is absent from many of the popular sites about SEO. My third link on a search for it was an article about why you shouldn’t use it. Reuters doesn’t use it properly (They include ‘By’, resulting in Facebook marking things as ‘By By Some Name’. It isn’t documented on Facebook at all. It isn’t in their debugger and it isn’t in their best practices. The use of this tag is a surprise to me and a bit of a mystery. This leads to another question: Open Graph has an author property that Facebook recognizes. What is it doing with that property if it isn’t using it to find author info?
Next!
I’m continuing to share to my wall with this methodology and I’m keeping track of what’s going on. I’m sure I’ll be writing about this again in the near future. If any of the hypotheses I proposed sound interesting perhaps you should try them out, see what happens and tell me all about it.

























.
Im Telefonsex Klinikum wird dir der Druck abgelassen und zwar aus allen Öffnungen.
Very nice post. I simply stumbled upon your blog and wanted to say
that I’ve really enjoyed surfing around your weblog posts.
After all I’ll be subscribing to your rss feed and I hope you write again soon!
What’s Happening i am new to this, I stumbled upon this I’ve discovered It positively
helpful and it has helped me out loads. I am hoping to
give a contribution & help different users like its aided
me. Great job.
[…] method for designating an author of an article shared on Facebook, Twitter, Google and LinkedIn is undocumented on those platforms. The `name=author` meta tag which is checked by most social sharing sites to determine authorship […]